Internet antes de la llegada de la Web: el protocolo Gopher
En estos días a nadie le resulta extraño incluir en alguna frase un “www…” y cada vez resulta más común hablar del protocolo HTTP(S), especialmente a raíz de su popularización de los últimos años. Pero, aunque parece que siempre han estado ahí, lo cierto es que se trata de tecnologías relativamente nuevas y que, antes de que llegaran a nuestros equipos, también había (ciber)vida. Como, por ejemplo, el protocolo Gopher.
¿Qué es el protocolo Gopher?
Mientras Tim Berners-Lee avanzaba en su gran proyecto, en 1991 se presentó en Minnesota el protocolo Gopher. El objetivo de este protocolo no era otro que facilitar la búsqueda de información y el acceso a los contenidos en un internet que prácticamente estaba empezando y, además, con el menor impacto en el cliente y en el servidor. Ambas condiciones eran igual de importantes, ya que hasta entonces no era posible acceder a la información mediante menús y las máquinas de la época no eran capaces de soportar la carga de las actuales. De esta forma, no solo se simplificaba la navegación, sino que se hacía accesible a todos los usuarios al ser Gopher compatible con los PCs personales del momento.
En líneas generales, podríamos decir que Gopher era el Google de la época, entendido como “la puerta a internet”. Un protocolo que permitía el acceso a los miles de servidores que existían en el momento y ponía al alcance del usuario la información almacenada.
¿Cómo funciona(ba)?
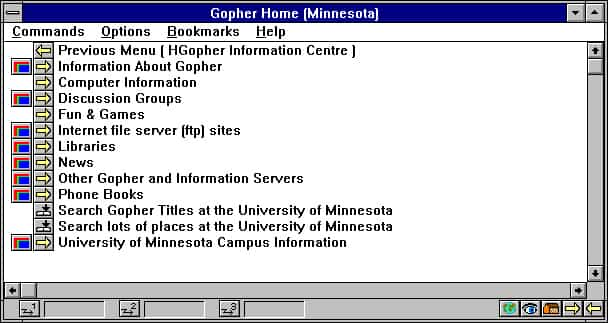
Gopher se basaba en facilitar al usuario una serie de menús formados por directorios, subdirectorios y los archivos, textos o HTML, que almacenaban como si fuera un sistema de ficheros. Para ello, toda la información se recogía en un “árbol”; donde los nodos permiten el acceso a los menús de las categorías inferiores o a “hojas”, el nivel último que contenía los textos. Era algo así como un servidor FTP: la información se divide en menús que a su vez contienen una serie de carpetas o archivos que pueden visualizarse o descargarse en el equipo con facilidad.
Aunque se compara a Gopher con la Web, se trata de un sistema incompleto. Es decir, la información está organizada de forma lógica y es posible pasar de un directorio a otro, pero no relacionar las hojas entre sí; ya que habría que esperar hasta 1993 para que se crearan los hiperenlaces.
En un abrir y cerrar (de enlaces)
El éxito de Gopher fue tal que en poco menos de un año se lanzó el primer gran motor de búsqueda para simplificar aún más las búsquedas en el espacio Gopher (o Gopherspace). En aquel momento unos 5000 servidores formaban el espacio Gopher. Veronica (acrónimo de “Very Easy Rodent-Oriented Netwide Index to Computerized Archives») es el nombre que se le dio a aquel motor de búsqueda. Motor y protocolo que no duraron mucho más, ya que en 1993 la historia de internet daría un giro. El giro.
Fue en ese año cuando Berners-Lee presentó al mundo la World Wide Web. Además, ocurrieron otros dos hechos que afectaron negativamente al auge de Gopher. Por un lado, se creó Moisac, un navegador web gráfico que apostaba por HTTP; además, la Universidad de Minnesota, la misma que creó Gopher, decidió licenciar su servicio. El hecho de tener que pagar por Gopher provocó recelos, que unidos al énfasis que se estaba poniendo en el protocolo HTTP, abocaron al fracaso a Gopher. A lo que habría que añadir la aparición de los archivos multimedia poco tiempo después. Algo que sí que era totalmente incompatible con un Gopher limitado a texto.
Hoy en día Gopher es un protocolo residual, entre otros motivos por que ya apenas existen tecnologías compatibles. Firefox dejó de darle soporte a partir de su versión 3 e Internet Explorer lo eliminó en 2002 cuando se descubrió un agujero de seguridad. En la actualidad solo puede utilizarse a través del navegador Lynx, el único que admite Gopher de forma nativa: O, también es posible recurrir a la extensión OverbiteFF en Firefox. Pero, si quieres consultar la información que quede en el “Gopherespacio” puedes recurrir a un servidor proxy.